Infrastruktur
Unsere Infrastruktur umfasst zwei Cluster: WIRKsam und Solar.
WIRKsam Cluster:
Das WIRKsam Cluster ist ein spezielles Forschungscluster für das verteilte Training von Machine Learning-Anwendungen auf umfangreichen Datensätzen. Es besteht aus zwei Head Nodes und acht Worker Nodes. Die interne Vernetzung erfolgt mit einer Geschwindigkeit von 2×10 Gigabit/s.
• SYS: PowerEdge R7525
• RAM: 512 GB DDR4
• CPU: 2x AMD EPYC 7313 16 Cores
• GPU: NVIDIA H100 PCIe
• HDD: 8x8TB NL-SAS
Solar Cluster:
Das Solar Cluster dient als Data-Lake und Infrastrukturcluster für interne Experimente und Leistungsmessungen. Es stellt eine umfassende Palette von Diensten, darunter Hadoop HDFS, Drill, Kafka und Spark bereit. Dieses Cluster besteht ebenfalls aus zwei Head Nodes und acht Worker Nodes, die intern mit einer Geschwindigkeit von 2×10 Gigabit/s vernetzt sind. Betelgeuse und Jupiter dienen als Jump Hosts in unserem Cluster, bieten Zugriff auf JupyterLab-Umgebungen und optimieren die Ressourcennutzung der Worker Nodes.
Worker Node Specs:
SYS: PowerEdge R740
RAM: 384 GB
CPU: 2x Xeon Gold 5115
HDD: 8x8TB NL-SAS
Betelgeuse Node:
Der leistungsstarke Betelgeuse Node ist ein wichtiger Bestandteil des Solar Clusters. Als Jump Host stellt er dedizierte JupyterLab-Umgebungen für ad-hoc Experimente (z.B. Abschlussarbeiten) und länger laufende Projekte zur Verfügung. Zudem fungiert er als Gateway-Server und ermöglicht über diverse Frameworks die effiziente Nutzung der Ressourcen der Worker Nodes.
SYS: PowerEdge R7525
RAM: 1024 GB DDR4
CPU: 2x AMD EPYC 7763 64Cores
GPU: NVIDIA A100 80GB PCIe
SSD: 6x 1,5TB
Jupiter Node:
Der Jupiter Node ist ebenfalls Teil des Solar Clusters. Wie der Betelgeuse Node fungiert er als Jump Host, stellt Interface und Speicherplatz in JupyterLab-Umgebungen für Projekte und Lehrveranstaltungen bereit. Er ermöglicht über verschiedene Frameworks die effektive Nutzung der Ressourcen der Worker Nodes.
SYS: PowerEdge R740
RAM: 288 GB
CPU: 2x Xeon Gold 5115
GPU: NVIDIA A100 40GB
HDD: 8x8TB NL-SAS
Mobile Data Science Workstation:
CPU: Intel Xeon w5-3435X (16 Cores)
RAM: 512GB DDR5
GPU: NVIDIA RTX A6000 (48GB)
SSD: 4x 4TB NVMe RAID
Data Group Nodes
Die Cluster bestehen jeweils aus acht Nodes. Die Nodes sind alle gleich aufgebaut:
Software
Im Big Data Lab kommen viele verschiedene Anwendungen koordiniert zum Einsatz, um die Dienste anzubieten. Wir setzen wann immer möglich auf quelloffene Software und passen die Dienste nach unseren Bedürfnissen an.
In der folgenden Übersicht ist unsere Lambda-Architektur erkennbar.
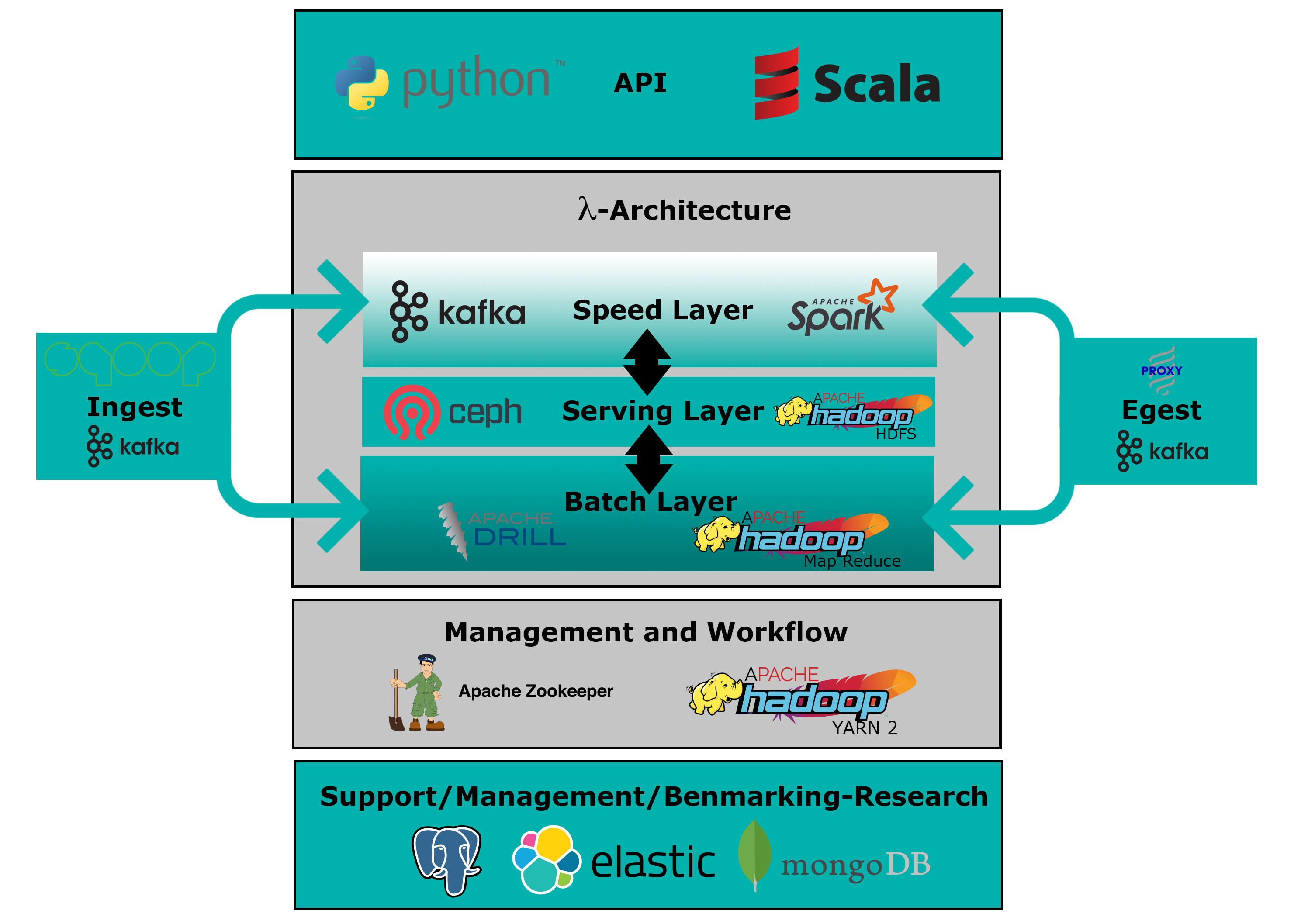
Die Daten werden über Apache Kafka eingespeist und innerhalb eines Hadoop HDFS persistiert. Der Zugriff auf persistierte oder im Stream befindliche Daten geschieht vorrangig über Drill Cluster oder Spark Worker. Wir bevorzugen die Entwicklung in Python 3.
Wir arbeiten auch mit gängigen Datenbankmanagementsystemen wie PostgreSQL und verteilten Datenspeichersystemen wie Elastic und MongoDB.
Die in der folgenden Abbildung dargestellte Software-Bibliothek bildet die Grundlage für die Analyse unserer Daten. Sie ermöglicht es uns, komplexe Daten zu verarbeiten, Erkenntnisse zu gewinnen und datenbasierte Entscheidungen zu treffen.
