Overview: We are looking for a motivated bachelor/master’s thesis student to work on a project focused on coverage path planning for measuring the parameters of helical blades using a robotic vision system. The thesis will involve motion planning using sequential sampling to ensure complete exposure of the object for accurate measurement. The project will leverage a Universal Robot (UR) equipped with a structured light or RGB-D camera to capture 3D data of metallic helix blades. Additionally, the student will tackle challenges in data reconstruction using a machine-learning approach to fill in missing features and improve the overall model.
The approach can be implemented and tested in a preconfigured simulation environment, as depicted in the image below, followed by a final evaluation on real-time hardware with a similar setup.
Key Objectives:
- Coverage Path Planning: A motion planning strategy utilizing the MoveIt2 ROS pipeline to plan the robot’s trajectory and ensure complete and systematic coverage of a helical blade. This approach ensures maximized exposure, accounting for factors like the robot’s reach and the camera’s field of view to avoid gaps in the data.
- Point Cloud Fusion: The process of merging multiple point cloud data sets captured at different poses of the robotic arm using transformations. This fusion creates an accurate 3D model of the helical blade, capturing all essential surface details and geometry.
- Handling Missing Data and Geometry Reconstruction: Addressing the issue of missing or incomplete data points in the point cloud caused by reflections from metallic surfaces and variations in ambient lighting. This step involves applying machine learning techniques, (supervised/unsupervised), to reconstruct missing features.
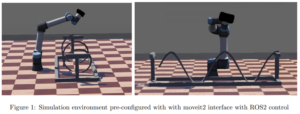
Requirements:
- Background in robotics, computer vision, or machine learning
- Experience with ROS, Python, or C++ is a plus
- Familiarity with point cloud processing (PCL, Open3D)
What You Will Gain:
- Hands-on experience with industrial robotics and vision-based measurement
- Gained knowledge in motion planning and coverage path planning using the MoveIt2 pipeline
- Possibility to implement the solution on real-time hardware in a production environment
- Brief introduction to setting up a simulation environment using Webots
Interested? Contact us at [email protected] for more details!
Initial Situation
Quality Inspection is a common task in modern industry. It is usually done by humans or inflexible expensive machines. If done automatically, most algorithms are based on classic computer vision despite them being outperformed by current state-of-the-art machine learning methods.
We developed and testing a new approach towards automating surface inspection in a company producing rear wings. This reliable way of generating a path for the camera based on a scan or CAD model allowed us to generate a new type of dataset for robotic inspection.
The surface inspection setup includes a robot arm with a calibrated camera mounted at theend-effector and a rear wing in a known and stable pose in front of the arm. This setup should be used for other products in the future as well.
There are already approaches for multi-pose anomaly detection (MPAD) in literature but they all rely on reconstruction. This thesis introduces a feature-based approach towards MPAD.
Goal
The main goal of this thesis is to design and implement feature-based MPAD algorithms and evaluate them against baselines on the given dataset.
A background in data science and computer vision is favorable. Prior Python knowledge (especially Pytorch) as well as knowledge of neural networks is required.
Completing this thesis will give you a chance to be part of a publication.
Contact Person
Matteo Tschesche
Email: [email protected]
Art der Arbeit: Bachelorarbeit/Masterarbeit
Ansprechpartner: Tobias Arndt
Das Thema
Künstliche Intelligenz bietet produzierenden Unternehmen enorme Potenziale, doch die Planung der zugrundeliegenden IT-Infrastruktur stellt besonders kleine und mittlere Unternehmen (KMU) vor große finanzielle und strategische Hürden. Etablierte Kostenmodelle wie Total Cost of Ownership (TCO) oder FinOps stammen aus einer Zeit planbarer IT-Ressourcen und greifen bei dynamischen KI-Workloads oft zu kurz. Sie ignorieren häufig KI-spezifische Kostentreiber wie den massiven Unterschied im GPU-Bedarf zwischen Modell-Training und Inferenz, die Kosten für Datenaufbereitung oder regulatorische Anforderungen wie den EU AI Act.
Genau hier setzt diese Masterarbeit an. Eingebettet in das BMBF-geförderte Kompetenzzentrum WIRKsam, welches den Strukturwandel im Rheinischen Revier durch KI begleitet, hast du die Möglichkeit, diese hochaktuelle Forschungslücke zu schließen.
Deine Mission
Ziel deiner Arbeit ist es, die Infrastrukturkosten industrieller KI-Anwendungen systematisch zu erfassen und zu bewerten, um KMU bei der Wahl der optimalen Bereitstellungsstrategie (Cloud, lokal oder hybrid) zu unterstützen. Basierend auf dem Design Science Research Ansatz analysierst du zunächst bestehende IT-Kostenframeworks auf ihre KI-Tauglichkeit und identifizierst deren Schwachstellen. Darauf aufbauend entwickelst du ein eigenes, erweitertes Kostenmodell.
Der besondere Reiz der Arbeit liegt in der direkten Praxisanwendung: Du evaluierst dein Modell an echten, hochaktuellen Use-Cases unserer Industriepartner. Du untersuchst beispielsweise, ob für große Sprachmodelle (LLMs) im industriellen Wissensmanagement eine Cloud-API oder ein lokales Modell sinnvoller ist, oder rechnest durch, welche Infrastruktur ein latenzkritisches Computer-Vision-System zur Qualitätskontrolle an der Produktionslinie benötigt.
Dein Profil & Unser Angebot
Wir suchen motivierte Masterstudierende (Wirtschaftsinformatik, Informatik, Wirtschaftsingenieurwesen oder vergleichbar), die sich für das Spannungsfeld zwischen IT-Management, Cloud-Technologien und angewandter KI begeistern. Du bringst analytisches Denkvermögen mit und hast idealerweise ein Grundverständnis für IT-Infrastrukturen und wirtschaftliche Bewertungsmethoden.
Wir bieten dir dafür ein exzellentes Forschungsumfeld an der Schnittstelle zwischen Wissenschaft und Industrie: Du erhältst Zugang zu echten Unternehmensszenarien im WIRKsam-Konsortium, wirst von erfahrenen Wissenschaftlern eng betreut und leistest einen direkten Beitrag zur KI-Adaption im Mittelstand. Zudem unterstützen wir gerne die gemeinsame Veröffentlichung deiner Arbeit auf einer Fachkonferenz.
Das Thema
Digitale Zerspanwerkzeuge sind in vielen produzierenden Unternehmen ein wichtiger Baustein zur Digitalisierung und Effizienzsteigerung interner Prozesse. Für ihre Bereitstellung müssen Werkzeugdaten aus verschiedenen Quellen zusammengeführt und in einen konsistenten Datenbestand überführt werden. Welche Informationen hierfür benötigt werden, hängt wesentlich von der korrekten Klassifikation des jeweiligen Werkzeugs ab. In der Praxis ist diese Zuordnung jedoch häufig mit aufwendiger manueller Recherche verbunden und erfordert das Erfahrungswissen einzelner Expertinnen und Experten. Eine systematische bildbasierte Suche nach ähnlichen Werkzeugen ist in vielen Fällen nicht vorhanden.
Die Masterarbeit setzt an diesem Problem an. Ziel ist die Entwicklung einer KI-basierten Pipeline, die anhand eines einzelnen Bildes ähnliche und potenziell passende Zerspanwerkzeuge in einem großen Datenbestand identifiziert.
Ihre Aufgabe
Im Rahmen der Arbeit wird eine Pipeline zur bildbasierten Ähnlichkeitssuche für Zerspanwerkzeuge entwickelt. Als Datengrundlage dienen reale Bilder und 3D-Modelle aus der von cimsource betriebenen Plattform für Werkzeugdaten.
Das Ziel besteht darin, zu einem gegebenen Eingabebild automatisch eine sortierte Liste ähnlicher Werkzeuge zu erzeugen. Die Ähnlichkeit soll dabei auf visuellen und geometrischen Merkmalen basieren. Hierzu kommen Verfahren aus Computer Vision, 3D-Datenverarbeitung und Machine Learning zum Einsatz.
Die Arbeit umfasst die Einarbeitung in Verfahren der bild- und 3D-basierten Ähnlichkeitssuche sowie in Ansätze des metrischen Lernens. Auf Basis der bereitgestellten 3D-Modelle, Bilder und Klassifikationen sind die Daten zu analysieren und aufzubereiten. Darauf aufbauend ist eine KI-Pipeline zu entwickeln.
Ihr Profil
Informatik, Wirtschaftsinformatik, Maschinenbau, Wirtschaftsingenieurwesen oder ein vergleichbarer Studiengang und Interesse an Forschung mit angewandter KI im industriellen Kontext.
Vorkenntnisse:
• gute Kenntnisse in Python
• Erfahrung mit Deep Learning Frameworks (bevorzugt PyTorch)
• Grundlagen in Computer Vision und Machine Learning
• Interesse an praxisnahen Industrieanwendungen
Die Arbeit wird in Kooperation mit der Firma CIMSource in Aachen durchgeführt.
Über CIMSource
Wir bieten dir ein praxisnahes und technisch anspruchsvolles Thema an der Schnittstelle zwischen KI und industrieller Anwendung:
• Zugriff auf reale, hochwertige Datensätze (3D Modelle, Bilder, Klassifikationen)
• enge Zusammenarbeit mit Industrieexperten im Bereich Zerspanung und Tool Data Management
• wissenschaftliche Betreuung und methodische Unterstützung
• die Möglichkeit, eine direkt verwertbare Lösung für die industrielle Praxis zu entwickeln
Hintergrund
Die Textilindustrie erfordert präzise Verfahren zur Erkennung und Klassifikation von Anomalien auf texturierten Oberflächen. Solche Anomalien können Hinweise auf Produktionsfehler oder Abweichungen von Qualitätsstandards geben. Ziel dieser Arbeit ist es, auf Basis moderner Deep-Learning-Methoden einen Ansatz zu entwickeln, der sowohl die Anomalien erkennt als auch die erkannten Anomalien klassifiziert. Ein zentraler Aspekt ist das Erlernen eines latenten Raumes, der sinnvolle, trennbare Repräsentationen von Texturpatches liefert.
Aufgabenstellung
Im Rahmen dieser Arbeit sollen folgende Schritte bearbeitet werden:
- Datensatz-Erstellung:
- Aufbau eines gelabelten Datensatzes mit texturierten Patches aus der Textilindustrie.
- Definieren von Anomalien und deren Klassifikationen.
- Latenter Raum und Anomalieerkennung:
- Erlernen eines sinnvollen latenten Raumes für die Patches unter Verwendung von metrischen Lernmethoden.
- Einsatz moderner Methoden des Deep Learning, insbesondere:
- MiniRocket2D
- Autoencoder
- Untrainierte Feature Extraktion mit vortrainierten Neuronalen Netzen
- Selbstüberwachtes Lernen (Die Abgrenzung zu den oben vorgestellten
Methoden stellt die Hauptarbeit dar)
- Klassifikation von Anomalien:
- Untersuchung von einfachen ML-Methoden wie k-NN zur Klassifikation der Anomalien im gelernten Raum.
- Analyse der Verwendung von Prototypen zur Repräsentation einzelner Klassen.
- Entwicklung einer Datenverarbeitungspipeline:
- Implementierung eines Dataloaders für die patchbasierte Verarbeitung der Daten.
- Pipeline für Training, Feature-Extraktion und Klassifikation.
- Methodenvergleich:
- Systematische Gegenüberstellung der Ergebnisse der verschiedenen Methoden des Feature-Lernens.
Ziele der Arbeit
- Entwicklung einer robusten und flexiblen Pipeline zur Anomalieerkennung und klassifikation auf textilen Texturen.
- Identifikation von Vor- und Nachteilen verschiedener Feature-Learning-Ansätze.
- Erstellung eines gelabelten Datensatzes für die textile Anomalieerkennung, der in zukünftigen Arbeiten als Benchmark dienen kann.
Betreuung und Unterstützung
Die Betreuung umfasst eine intensive Einführung in die Methoden des Deep Learning und metrischen Lernens, regelmäßige Feedback-Sitzungen sowie Unterstützung bei der Implementierung und Analyse. Der/die Studierende wird außerdem Zugang zu relevanten Ressourcen wie GPU-Rechnern und Fachliteratur erhalten.
Ziel der Arbeit ist, eine Self-Organizing Feature Map (SOFM) in pytorch zu implementieren. Dabei soll die Anzahl der Dimensionen frei wählbar sein und die SOFM am Ausgang mit einer Klassifikationsschicht versehen werden.
Die SOFM ist eine bekannte Architektur Neuronaler Netze, die unüberwacht lernen kann und durch Nachtrainieren auch zur Klassifikation geeignet ist. Anders als z.B. Feed-ForwardNetze, wie sie im Deep-Learning eingesetzt werden, kann die SOFM Eingaben nicht nur einer vorgegebenen Klasse zuordnen, sondern bietet auch die Klasse „unbekannt“ als inhärentes Merkmal der Architektur an.
Die Arbeit soll den aktuelle Veröffentlichungen zur SOFM in einer LIteraturrecherche
analysieren und eine SOFM in pytorch so implementieren, dass die Dimensionalität der
SOFM als Hyperparameter vorgegeben werden kann.
Bei vorhandensein eines gelabelten Datensatzes zum Training, soll eine Ausgabeschicht an die SOFM angehangen werden, so dass ein Klassifikator entsteht. Dabei sind die Konventionen von pytorch beim Design der API zu berücksichtigen.
Beschreibung:
Ziel dieser Bachelorarbeit ist es, einen Demonstrator zur Visualisierung neuronaler Netzwerke zu entwickeln. Die Visualisierung soll dabei die aktuellen Aktivierungen der Faltungsebenen und des Feed-Forward Netzes parametrisierbar darstellen („Level-OfDetail“). Der Demonstrator soll dabei ein von einer Kamera aufgenommenes Bild, als Echtzeitvisualisierung auf einem Bildschirm, einschließlich des Zugeordneten Objektes darstellen.
Aufgabenstellung:
- Recherche: Führen Sie zu Beginn der Arbeit eine umfassende Literaturrecherche durch, um den Stand der Technik zur Visualisierung Neuronaler Netze zu erheben. Recherchieren Sie ebenfalls, welche Tools und Ansätze zur Visualisierung neuronaler Netzwerke bereits existieren und analysieren Sie deren Stärken und Schwächen.
- Visualisierung: Entwerfen und implementieren Sie eine Visualisierungslogik, die die Aktivierung der Faltungslayer und des Feed-Forward-Netzes darstellt. Die Darstellung soll dabei auf klarer und ästhetischer Weise alle relevanten Schichten eines neuronalen Netzwerks, wie Convolutional Layers, Dense Layers, Pooling, Dropout, Skip Connections, etc., wiedergeben.
- Parametrisierung: Die Komponenten der Netzarchitektur sollen parametrisierbar sein, Z.B, welche Schichten visualisiert werden oder ob nur ein Teil der Aktivierungen eines Layers dargestellt werden.
- Erweiterbarkeit: Die Architektur des Tools sollte es ermöglichen, zukünftige
Erweiterungen vorzunehmen, z.B. die Integration von Netzwerkbeschreibungen oder die Anpassung der Visualisierungsdarstellung für spezielle Netzarten (z.B. RNNs, GANs).
Voraussetzungen:
- Gute Kenntnisse in Python und den Frameworks Keras und ONNX.
- Interesse an der Entwicklung von Tools für das maschinelle Lernen.
Ziel der Arbeit:
Das Ergebnis dieser Arbeit soll ein nutzerfreundliches Visualisierungstool sein, das komplexe neuronale Netzwerke auf verständliche Weise darstellt. Der Fokus liegt auf der detaillierten und parametrisierbaren Visualisierung, die nicht nur die Architektur selbst, sondern auch deren spezifische Parameter und Funktionen greifbar macht. Besonders wichtig ist, dass das Tool auf Basis der Recherche Erkenntnisse aus modernen Netzarchitekturen wie Skip Connections oder U-Net-artigen Strukturen integriert.
Beschreibung:
Ziel dieser Bachelorarbeit ist es, ein Tool zur Visualisierung neuronaler Netzwerke zu entwickeln, das aus den Dateiformaten ONNX (Open Neural Network Exchange) oder einer Keras Functional API-Beschreibung neuronale Netzwerke einliest und diese als SVG (Scalable Vector Graphics) darstellt. Die Visualisierung soll dabei nicht nur die Netzstruktur zeigen, sondern auch alle wichtigen Komponenten und Parameter der einzelnen Layer (wie z.B. Anzahl der Neuronen, Aktivierungsfunktionen, Filtergrößen) interaktiv und parametrisierbar darstellen. Insbesondere soll dabei ein klares Verständnis und dem konkreten Ablauf des Prozesses der Datenverarbeitung- und Veränderung aus den Visualisierungen sichtbar werden. Diese können zum Beispiel konkrete Bilder sein.
Aufgabenstellung:
- Recherche: Führen Sie zu Beginn der Arbeit eine umfassende Literaturrecherche durch, um die wichtigsten Komponenten neuronaler Netzwerke zu identifizieren, die in der Visualisierung berücksichtigt werden sollten. Zu diesen Komponenten zählen u.a. Skip Connections, Residual Layers, oder spezifische Architekturen wie U-Net. Recherchieren Sie ebenfalls, welche Tools und Ansätze zur Visualisierung neuronaler Netzwerke bereits existieren und analysieren Sie deren Stärken und Schwächen.
- Eingangsformat: Entwickeln Sie ein Parser-Modul, das ONNX-Dateien und Keras Functional API-Beschreibungen einlesen und in einer strukturierten Form abbilden kann.
- Visualisierung: Entwerfen und implementieren Sie eine Visualisierungslogik, die die Netzarchitektur in Form von SVG-Dateien darstellt. Die Darstellung soll dabei auf klarer und ästhetischer Weise alle relevanten Schichten eines neuronalen Netzwerks, wie Convolutional Layers, Dense Layers, Pooling, Dropout, Skip Connections, etc., wiedergeben.
- Parametrisierung: Die Komponenten der Netzarchitektur sollen interaktiv parametrisierbar sein. Beispielsweise sollen Änderungen der Anzahl von Neuronen oder der Filtergröße in Echtzeit in der SVG-Darstellung reflektiert werden können.
- Erweiterbarkeit: Die Architektur des Tools sollte es ermöglichen, zukünftige Erweiterungen vorzunehmen, z.B. die Integration von anderen Netzwerkbeschreibungen (z.B. PyTorch) oder die Anpassung der Visualisierungsdarstellung für spezielle Netzarten (z.B. RNNs, GANs).
Voraussetzungen:
- Gute Kenntnisse in Python und den Frameworks Keras und ONNX.
- Erfahrung mit der Erstellung von SVG-Grafiken oder ähnlichen Visualisierungsformen.
- Interesse an der Entwicklung von Tools für das maschinelle Lernen.
Ziel der Arbeit:
Das Ergebnis dieser Arbeit soll ein nutzerfreundliches Visualisierungstool sein, das komplexe neuronale Netzwerke auf verständliche Weise darstellt. Der Fokus liegt auf derdetaillierten und parametrisierbaren Visualisierung, die nicht nur die Architektur selbst, sondern auch deren spezifische Parameter und Funktionen greifbar macht. Besonders wichtig ist, dass das Tool auf Basis der Recherche Erkenntnisse aus modernen Netzarchitekturen wie Skip Connections oder U-Net-artigen Strukturen integriert.
Betreuung:
Tobias Arndt, [email protected], gerne direkt über WebEx kontaktieren
Overview: We are seeking a motivated bachelor’s or master’s student for a thesis on 3D geometry reconstruction and parameter extraction of helical blades using a vision system. The project involves merging point clouds from different poses using a structured light or RGB-D camera to create a complete 3D model. Challenges like missing data due to reflections and lighting variations will be addressed using machine learning techniques. Key parameters, such as radius, pitch, and twist of the blade will be extracted from the processed point cloud. The approach will be tested in simulation before evaluation on real hardware.
Key Objectives:
- Point Cloud Merging: To explore different approaches to align and merge multiple point cloud datasets captured from different camera poses to create a unified and accurate 3D representation of the helical blade.
- Handling Missing Data and Geometry Reconstruction: Addressing the issue of missing or incomplete data points in the point cloud caused by reflections from metallic surfaces and variations in ambient lighting. This step involves applying machine learning techniques, (supervised/ unsupervised), to reconstruct missing features.
- Parameter Extraction: Extract key parameters of the helical blade, such as the radius, pitch, and twist from the reconstructed model. This step will involve applying geometric analysis techniques to accurately quantify the properties of the blade and compare them with the desired specifications.
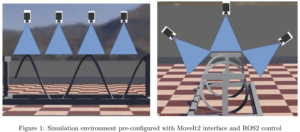
Requirements:
- Background in robotics, computer vision, or machine learning
- Experience with ROS, Python, or C++ is a plus
- Familiarity with point cloud processing (PCL, Open3D)
- Basic knowledge of geometric analysis and parameter extraction from 3D models
What Will You Gain:
- Hands-on experience with industrial robotics and vision-based measurement
- Opportunity to implement the solution on real-time hardware in a production environment
- Brief introduction to setting up a simulation environment using Webots
Interested? Contact us at [email protected] for more details!
Ausgangssituation
Der Unternehmenspartner stellt Filter für die Automobilindustrie her, die zu sicherheitskritischen Bauteilen gehören. Daraus leiten sich hohe Qualitätsansprüche ab, die derzeit durch manuelle Kontrollen erfüllt werden.
Der Unternehmenspartner produziert nahezu (ungefähr 95%) fehlerfrei, sodass sehr viele Datenpunkte zu korrekt produzierten Bauteilen vorliegen.
Methoden des maschinellen Lernens und der künstlichen Intelligenz stellen vielversprechende Ansätze dar, die nachhaltig dabei helfen können, den manuellen Prüfaufwand zu reduzieren.
Rekontruktionsbasierte Anomalieerkennungsalgorithmen reduzieren den Informationsgehalt des zu betrachtenden Bildes durch verschiedene Methoden (beispielsweise durch Rauschen, Ausschneiden und Tauschen von Bildteilen) und trainieren auf diesen Bildern ein neuronales Netzwerk darauf, diese Bilder wieder so zu rekonstruieren, dass sie möglichst ähnlich zum Original sind. Dadurch dass auf möglichst anomalie-freien Bildern trainiert wird, sollen Anomalien mit größeren Rekonstruktionsfehlern erstellt werden und damit aussortiert werden.
Diese rekonstruierten Bilder unterscheiden sich für das menschliche Auge oft gut vom Originalbild bei Anomalien im Vergleich zu normalen Bildern und dennoch werden solche Bilder oft als Anomalie markiert. Das liegt an hohen Varianzen der Pixel im Bild an sich und an einfachen Schwellenwertverfahren mit denen der Unterschied berechnet wird.Die Nutzung von Methoden des machinellen Lernens auf diesen rekonstruierten Bildern bietet die Möglichkeit bessere Ergebnisee für die Anomalieerkennung zu gewinnen.
Ziel
Ziel dieser Arbeit ist es sich mit bereits implementierten rekonstruktionsbasierten Anomalieerkenungsmethoden auseinanderzusetzen und darauf aufbauend Methoden zu recherchieren, die benutzt werden können um die Ergebnisse der Anomalieerkennung auf diesen Bildern zu erhöhen.
Das beinhaltet vor allem die Kombination mehrerer Bildern und das Lernen von Klassifikatoren. Diese Verfahren der Klassifikation sollen evaluiert werden und Rückschlüsse ebenfalls auf die Nutzung verschiedener rekonstruktionsbasierter Ansätze ziehen.
Pythonkenntnisse (insbesondere Pytorch) sowie Vorkenntnisse über neuronale Netzwerke
sind von Vorteil.
Aufgaben
- Untersuchung der Einsatzmöglichkeiten von Klassifikationsmethoden auf rekonstruierten Bildern für die Anomalieerkennung
- Implementierung, Einbindung und Training von diesen Klassifikatoren auf unterschiedlichen rekonstruktionsbasierten Anomalieerkennungsalgorithen und auf unterschiedlichen Datensätzen
- Anpassungen/Optimierung der Modelle und Evaluation
Dein Benefit
- Lernen von immer wichtiger werdenden Technologien, in einem Umfeld ohne technische Limitierungen. (Arbeit auf Cluster mit den leistungsfähigsten Grafikkarten zur Zeit der Ausschreibung)
- Kenntnisse über aktuelle Ansätze neuronaler Netzwerke für Klassifikationsprobleme
erlernen - Möglichkeit Teil einer Veröffentlichung zu werden.
Ansprechpartner
Matteo Tschesche
E-Mail: [email protected]
Art der Arbeit: Bachelorarbeit + Praxisprojekt
Ansprechpartner: Marcel Remmy, Oskar Galla, Max Conzen
Technologien: Python (v2/v3), Dask, Zarr, Icechunk, HDF5, TensorStore, S3/Object Storage
1. Ausgangssituation & Motivation
Die effiziente Speicherung und Abfrage massiver n-dimensionaler Datenmengen (z.B. Klimadaten, Mikroskopie oder Simulationen) stellt moderne Big-Data-Infrastrukturen vor große Herausforderungen. Während klassische Formate wie HDF5 lokal etabliert sind, drängen neue, Standards wie Zarr (inkl. Erweiterungen wie Icechunk für Versionierung und obstore) sowie hochperformante Bibliotheken wie Googles TensorStore auf den Markt. Besonders die Performance-Unterschiede bei der Skalierung von einer Single-Node-Umgebung hin zu verteilten Clustern (z.B. via Dask) sind bisher unzureichend systematisch verglichen worden.
2. Ziel der Arbeit
Ziel der Arbeit ist ein umfassendes Benchmarking des Durchsatzes (Throughput) beim Lesen und Schreiben großer n-dimensionaler Arrays. Dabei sollen die Performance-Charakteristika verschiedener Speicherbackends und Bibliotheken sowohl lokal als auch im verteilten Betrieb analysiert werden, um Best-Practices für zukünftige Big-Data-Architekturen abzuleiten.
3. Aufgabenstellung
- Recherche & Setup: Einarbeitung in die Spezifikationen von Zarr (V2/V3), Icechunk, TensorStore und HDF5-Varianten (object storage lokal vs. verteilt).
- Implementierung der Test-Suite: Entwicklung einer automatisierten Benchmark-Pipeline in Python, die folgende Stacks abdeckt:
- Zarr Ökosystem: Zarr V2 vs. Zarr V3 (unter Einbeziehung von icechunk und obstore).
- HDF5: Vergleich klassischer Ansätze und moderner Cloud-Layer.
- TensorStore: Evaluation der Google-Library für Multi-Dimensional Arrays.
- Performance-Messung:
- 1-Node Cluster: Baseline-Messungen des Durchsatzes bei lokaler IO-Last.
- 4-Node Cluster: Skalierungstests unter Nutzung von Dask zur Lastverteilung im Netzverbund.
- Ausgewählte Datensets als Szenarien für verschiedene Konfigurationen
- Analyse: Auswertung der Latenz- und Durchsatzwerte in Abhängigkeit von Chunk-Größen, Kompressionsraten und Parallelisierungsgrad.
4. Voraussetzungen
- Sehr gute Kenntnisse in Python
- Interesse an verteilten Systemen und High-Performance Storage
- Idealerweise erste Erfahrungen mit Dask oder Object Storage wie S3
- Sicherer Umgang mit Linux-Umgebungen (SSH, CLI).
5. Dein Benefit
- High-End Infrastruktur: Zugriff auf unsere Cluster-Ressourcen für realistische Multi-Node-Szenarien.
- Aktuelle Forschung: Du arbeitest an der Speerspitze neuer Datenformate (wie z.b. Icechunk).
- Industrierelevanz: Die Ergebnisse sind direkt relevant für Unternehmen und wissenschaftliche Projekte.
- Enges Mentoring: Unterstützung bei der Architektur der Benchmark-Suite und der statistischen Auswertung.
Art der Arbeit: Bachelorarbeit + Praxisprojekt
Ansprechpartner: Marcel Remmy
Technologien: NVIDIA Jetson, JetPack, vLLM/Ollama
1. Ausgangssituation & Motivation
Die Ausführung von Large Language Models (LLMs) am „Edge“ ermöglicht datenschutzkonforme und offline-fähige KI-Anwendungen. Während ein einzelner NVIDIA Jetson bereits kleine Modelle (SLMs) effizient berechnen kann, stoßen komplexe Aufgaben wie Coding-Unterstützung oder tiefgehende Textanalyse oft an die Speichergrenzen einzelner Module. Durch das Zusammenschalten mehrerer Jetsons zu einem Cluster (Multi-Node-Inferenz) lässt sich der verfügbare VRAM bündeln, um größere, leistungsfähigere Modelle (z.B. 14B oder 32B Parameter) lokal zu betreiben.
2. Ziel der Arbeit
Das Ziel dieser Arbeit ist der Aufbau und Benchmark eines Jetson-Clusters für die LLM-Inferenz. Es soll untersucht werden, wie sich die Skalierung auf mehrere Knoten auf die Latenz (TTFT) und den Durchsatz (TpS) auswirkt. Parallel dazu werden spezialisierte Modelle auf ihre Eignung für Coding-Aufgaben und Textzusammenfassungen unter Ressourcenbeschränkung getestet.
3. Aufgabenstellung
Hardware-Setup & Orchestrierung:
– Aufsetzen der NVIDIA Jetson Hardware mit aktuellem JetPack.
– Konfiguration eines leichtgewichtigen Clusters zur Verteilung der Inferenzlast.
Inferenz-Stack Implementierung:
– Deployment von Inferenz-Engines wie vLLM oder llama.cpp im Cluster-Verbund.
– Untersuchung von Quantisierungsmethoden (INT4/FP8), um die Modelle optimal in den Unified Memory der Jetsons zu laden.
Modell-Evaluation (Coding & Text):
– Benchmark von Modellen wie z.B. Llama 3.2 (3B/11B), Qwen 2.5 Coder und DeepSeek-R1 hinsichtlich Genauigkeit und Geschwindigkeit.
– Test von Coding-Szenarien (z.B. Python-Funktionsgenerierung) und Textanalyse (z.B. Extraktion von Metadaten aus langen Dokumenten).
Skalierungsanalyse:
– Vergleich: Single-Node vs. Multi-Node (z.B. 2er- vs. 4er-Cluster).
– Analyse des Overheads durch die Netzwerkkommunikation zwischen den Knoten.
4. Voraussetzungen
– Grundkenntnisse in Linux (Ubuntu) und Docker/Containern.
– Interesse an Hardware-naher Softwareentwicklung und KI-Modellen.
– Erfahrung mit Python ist erforderlich; Kenntnisse in Kubernetes/K3s sind von Vorteil, aber kein Muss.
5. Dein Benefit
– Hands-on Hardware: Du arbeitest direkt mit NVIDIA-Edge-Hardware des Big Data Lab.
– Zukunftsthema Cluster-Computing: Lerne, wie man KI-Modelle verteilt berechnet (Distributed Inference).
– Deep Learning Expertise: Tiefes Verständnis für Quantisierung und Optimierung von LLMs.
Art der Arbeit: Bachelorarbeit + Praxisprojekt
Ansprechpartner: Marcel Remmy, Oskar Galla, Max Conzen
Technologien: Python, Parquet, DuckDB, Zarr, TensorStore, MKV/FFmpeg, Hugging Face Datasets
1. Ausgangssituation & Motivation
In modernen KI- und Big-Data-Anwendungen fallen unterschiedlichste Datentypen an: von klassischen strukturierten Tabellen über multivariate Zeitreihen ( Sensordaten, Gravitationswellen, etc.) bis hin zu unstrukturierten Mediendaten (Video/Audio). Jede Datenklasse stellt eigene Anforderungen an Kompression, Suchgeschwindigkeit und Memory-Footprint. Während Parquet der Standard für Tabellen ist, etablieren sich für KI-Workflows Formate wie Zarr (für Arrays) oder DuckDB (für schnelle In-Process-Abfragen). Es fehlt an einem systematischen Vergleich der Python-Bibliotheken, der zeigt, welche Kombination aus Format und Library für welchen Datentyp in einer AI-Pipeline die optimale Performance liefert.
2. Ziel der Arbeit
Das Ziel der Arbeit ist die Identifikation und das Benchmarking der „Best-in-Class“ Python-Bibliotheken für verschiedene Datenklassen. Dabei soll untersucht werden, wie sich spezialisierte Formate (z.B. TensorStore für Deep Learning) gegenüber Allround-Lösungen schlagen und welche Bibliotheken die effizienteste Brücke zwischen Speicherformat und KI-Frameworks (PyTorch/TensorFlow) schlagen.
3. Aufgabenstellung
Klassifizierung der Datentypen: Definition repräsentativer Datensätze für:
- Strukturierte Daten: Tabellarische Metadaten (Parquet, ORC, DuckDB).
- N-Dimensionale Arrays: Bildstapel, Sensordaten (Zarr, TensorStore, HDF5).
- Multivariate Zeitreihen: Hochfrequenz-Sensordaten (Parquet, Zarr, ArcticDB).
- Mediendaten: Video-Streams und AI-optimierte Container (MKV, DMLC, NVIDIA VPF).
Bibliotheken-Survey: Recherche und Auswahl der performantesten Python-Wrapper (z.B. pyarrow, zarr-python, duckdb, tensorstore).
Benchmarking:
- Messung von Read/Write-Latenz und Durchsatz.
- Vergleich der Kompressionsraten (Storage-Effizienz).
- Evaluierung des Random-Access (Punktuelle Abfragen vs. Full-Scans).
Integrationstest: Bewertung der Kompatibilität mit KI-Datenladern (z.B. Integration in Hugging Face datasets oder PyTorch DataLoaders).
4. Voraussetzungen
- Studium der Informatik, Data Science oder Ingenieurinformatik.
- Fundierte Kenntnisse in Python (Pandas, NumPy).
- Grundverständnis von Serialisierung und Dateisystemen.
- Interesse an der Optimierung von Daten-Pipelines für Machine Learning.
- Eigenständige Arbeitsweise bei der Evaluierung neuer Bibliotheken.
5. Dein Benefit
- Expertenwissen: Du wirst zum Experten für das „Data Engineering“-Backend von (KI-) Systemen.
- Modernster Stack: Du arbeitest mit Tools wie DuckDB und TensorStore, die gerade die Industrie revolutionieren.
- Praxisrelevanz: Deine Ergebnisse dienen als Blaupause für die Architektur künftiger Big Data Lab-Projekte.
- GPU-Cluster: Nutzung unserer Infrastruktur zur Simulation großer Lastszenarien.
Art der Arbeit: Bachelorarbeit/Masterarbeit
Ansprechpartner: Tobias Arndt
In Kooperation mit der Verseidag
Hintergrund
Moderne Feature-Extraktoren wie DINOv2, CLIP oder ConvNeXt lernen latente Räume, die erstaunlich reichhaltige semantische Strukturen abbilden – oft ohne jede aufgabenspezifische Anpassung. Diese Repräsentationen sind nicht nur für die Modelle selbst nützlich, sondern lassen sich als Grundlage *für* nachgelagerte, leichtgewichtige Klassifikatoren verwenden. Genau hier setzt diese Arbeit an: Anstatt einen monolithischen Klassifikator End-to-End zu trainieren, nutzen wir die gelernten Features als festen (oder minimal angepassten) Ausgangspunkt und trainieren darauf ein Prototypen-Netzwerk. Der entscheidende Vorteil gegenüber klassischen Softmax-Klassifikatoren liegt in der Flexibilität: Klassen können zur Laufzeit hinzugefügt oder weggelassen werden, ohne das Modell neu zu trainieren – eine Eigenschaft, die in der industriellen Praxis bei wechselnden Kundenanforderungen und Produktpaletten von großem Wert ist.
Zentrale Fragestellung
Die Arbeit untersucht systematisch, wie leichtgewichtig ein solches System gestaltet werden kann und welche Trainingsstrategie das beste Verhältnis aus Aufwand und Klassifikationsleistung liefert. Konkret stehen verschiedene „Rezepte“ im Fokus, die sich in der Anzahl der Trainingsschritte und dem Grad der Modellanpassung unterscheiden:
Rezept 1 – Statischer Feature-Extraktor. Der vortrainierte Backbone wird eingefroren, die Features einmalig extrahiert. Ausschließlich das Prototypen-Netzwerk (bzw. die Distanzmetrik im latenten Raum) wird trainiert. Dies ist der leichtgewichtigste Ansatz und erlaubt Klassifikation mit minimalem Rechenaufwand.
Rezept 2 – Zweistufiges Finetuning. In einer ersten Stufe wird der Feature-Extraktor mit einer modernen metrischen Loss-Funktion (z. B. SupCon, ArcFace, ProxyNCA++) auf die Zieldomäne feinjustiert, um den latenten Raum domänenspezifisch zu schärfen. In der zweiten Stufe werden auf den angepassten Features die Klassenprototypen berechnet und das Prototypen-Netzwerk evaluiert. Die zentrale Frage ist, ob dieser Mehraufwand die Flexibilität des Systems rechtfertigt.
Rezept 3 – Prototypen als Evaluationsmetrik. Hier wird untersucht, ob die Klassenprototypen selbst – also die Mittelwerte der Feature-Vektoren pro Klasse – bereits als vollwertiger Klassifikator ohne weiteres Training dienen können. Dies wäre die minimalste Pipeline überhaupt: Features extrahieren, Mittelwerte bilden, per Nearest-Centroid klassifizieren.
Die Arbeit soll diese Rezepte systematisch vergleichen und herausarbeiten, bei welchem Komplexitätsgrad welche Klassifikationsleistung erreicht wird – insbesondere auch unter der Bedingung, dass bestimmte Klassen gezielt aus- oder eingeschlossen werden.
Aufgaben
Die Arbeit umfasst eine kompakte Literaturrecherche zu Prototypical Networks, metrischem Lernen und modernen Feature-Extraktoren, gefolgt von der Implementierung und dem systematischen Vergleich der beschriebenen Trainingsrezepte auf industriellen Bilddaten der Verseidag. Besonderes Augenmerk liegt auf der Evaluation unter realistischen Bedingungen: Wie verhält sich das System, wenn Klassen dynamisch hinzugefügt oder entfernt werden? Wie robust ist es gegenüber Klassenungleichgewichten? Und wie steht der jeweilige Trainingsaufwand im Verhältnis zum Genauigkeitsgewinn?
Industriekontext
Die Verseidag stellt als Kooperationspartner reale Bilddaten aus dem Bereich technischer Textilien und Beschichtungen bereit. Der direkte Praxisbezug stellt sicher, dass die entwickelten Methoden nicht nur akademisch, sondern auch industriell tragfähig sind.
Voraussetzungen
Gute Python- und PyTorch-Kenntnisse. Grundlagen in Computer Vision und Deep Learning. Eigenständige Arbeitsweise und Interesse an industrienaher Forschung.
Art der Arbeit: Bachelorarbeit
Ansprechpartner: Tobias Arndt
Hintergrund
Unser Ziel ist es, Zusammenhänge zwischen Qualitätsdaten und potenziellen Einflussfaktoren auf die Produktqualität zu untersuchen. Die Datengrundlage hierfür bilden Qualitätsprüfkarten der letzten 10 Jahre, die in Form von Scans vorliegen.
Die Nutzbarmachung dieser historischen Daten stellt uns vor Herausforderungen: Die Dokumente weisen teilweise abgeschnittene Ränder auf und enthalten handschriftliche Zahlen. Um diese Rohdaten für weiterführende Machine-Learning-Analysen nutzbar zu machen, soll im Rahmen dieser Bachelorarbeit eine automatisierte Pipeline zur Datenextraktion und -transformation entwickelt und evaluiert werden.
Deine Aufgaben
* Bildvorverarbeitung (Image Preparation): Optimierung der vorhandenen Scans (z. B. Umgang mit fehlenden/abgeschnittenen Bildrändern).
* Computer Vision & Extraktion: Evaluierung und Anwendung von Machine-Learning-Algorithmen für die folgenden Bereiche:
* Erkennung des Dokumentenlayouts
* Texterkennung (OCR) für gedruckte Inhalte
* Handschrifterkennung (HTR), insbesondere für geschriebene Zahlen
* Erkennung von Checkboxen
* Datenaufbereitung: Transformation der erkannten visuellen Informationen in strukturierte, maschinenlesbare Datensätze.
* Datenanalyse & Ausblick: Durchführung erster statistischer Auswertungen auf den gewonnenen Daten und (sofern zeitlich möglich) Erprobung weiterführender ML-Modelle (z. B. Künstliche Neuronale Netze / ANN oder XGBoost), um Zusammenhänge im Qualitätskontext aufzuzeigen.
Dein Profil
* Du studierst Informatik, Data Science, Wirtschaftsinformatik, Mathematik, Ingenieurwissenschaften oder einen vergleichbaren Studiengang.
* Du hast starkes Interesse an Datenverarbeitung, Machine Learning und idealerweise Computer Vision.
* Du bringst Programmierkenntnisse mit (bevorzugt in Python).
* Erste Erfahrungen im Umgang mit JupyterLab für die Datenaufbereitung sowie Grundlagenwissen in ML-Themen sind von Vorteil (wir haben hier bereits Expertise im Team und unterstützen dich gerne).
* Du arbeitest strukturiert, eigenständig und hast Spaß am Lösen komplexer Probleme.
Wir bieten
* Ein hochaktuelles, praxisnahes Thema mit industrieller Relevanz und echten, historischen Datensätzen.
* Erfahrene Betreuung im Bereich Data Science, JupyterLab und Machine Learning.
* Die Möglichkeit, mit deiner Arbeit den Grundstein für zukünftige KI-Projekte in unserer Qualitätssicherung zu legen.
Art der Arbeit: Bachelorarbeit + Praxisprojekt
Ansprechpartner: Marcel Remmy, Oskar Galla, Max Conzen
Technologien (vorschl.): HTCondor, Slurm, Kubernetes/K3s (Batch-Workloads), BOINC-Ökosystem/Volunteer-Computing-Ansätze, Container (Docker/Apptainer), Linux, Python für Benchmarking & Auswertung
1. Ausgangssituation & Motivation
Viele Organisationen verfügen über Hardware, die zeitweise ungenutzt ist und sich prinzipiell als Compute-Pool für Batch-Jobs, Data-Science-Workloads oder wissenschaftliche Rechenaufgaben eignet.
Frameworks wie HTCondor adressieren genau dieses Problem. Es existieren weitere Scheduler- und Cluster-Ökosysteme (z.B. Slurm, Kubernetes-basierte Batch-Systeme) sowie Volunteer-Computing-Ansätze, die ähnliche Ziele mit unterschiedlichen Annahmen (Trust, Administration, Netzwerk, Heterogenität) verfolgen.
2. Ziel der Arbeit
Ziel der Arbeit ist eine systematische Untersuchung und Gegenüberstellung ausgewählter Frameworks für dynamische Cluster- und Batch-Orchestrierung (insbesondere HTCondor) hinsichtlich Funktionsumfang, Betriebsmodell und bestgeeigneten Einsatzszenarien.
Die Arbeit soll aufzeigen, welches Framework unter welchen Randbedingungen (z.B. dynamische Nodes, heterogene Hardware, Security/Isolation, administrativer Aufwand) „am besten passt“.
3. Aufgabenstellung
3.1 Bewertungskriterien & Use-Case-Definition
- Festlegung von Bewertungskriterien (z.B. Installation, Scheduling-Funktionen, Ressourcenerkennung, Observability, Heterogenität, WAN/LAN-Tauglichkeit).
3.2 Framework-Survey & Auswahl
Recherche und Architekturvergleich von Kandidaten, z.B HTCondor, Slurm und ein Kubernetes-basierter Batch-Ansatz sowie BOINC/Volunteer-Computing-Stacks.
Einordnung der Systeme nach Zielbild (HPC-Cluster, opportunistische Pools, volunteer/untrusted).
3.3 Implementierung
- Entwurf von benchmarks auf Labor-hardware.
- Dokumentation von Setup-Aufwand, nötigen Komponenten (Controller/Worker), typischen Konfigurationsschritten und Betriebs-/Update-Konzepten.
4. Voraussetzungen
- Sicherer Umgang mit Linux-Umgebungen (SSH, CLI) und Interesse an verteilten Systemen.
- Optional: Erste Erfahrung mit Kubernetes/Docker oder HPC-Umgebungen.
Art der Arbeit: Bachelorarbeit/Masterarbeit
Ansprechpartner: Ingo Elsen
Hintergrund
Seismic disturbances propagate through the rock surrounding ET’s mirrors as seismic waves. These waves introduce variations in the density of the rock and cause minuscule shifts of the cavern walls. Both effects cause the mirrors to accelerate; the resulting movement generates noise – known as Newtonian Noise (NN) – at the output of the interferometers, which limits sensitivity at the lowest frequencies. Since gravitational forces cannot be shielded, there are no technical means of suppressing NN.
However, it is possible to detect the seismic waves using seismic cages, which are seismometer networks that enclose the mirrors, to determine the expected movement of the mirrors and to correct it. The correction is known as Active Noise Mitigation (ANM). The correction can be implemented either offline, by subtracting the expected light output from the data, or online, by calculating the correction in real time and injecting a correction signal into the mirrors‘ longitudinal control loop. The second approach is more challenging, but has the advantage that the correction already applies to the low-latency pipelines that identify potential events for multi-messenger observation, whereby low noise in this frequency range is particularly important for sky localisation. The correction is complicated by the fact that the influence of seismic waves on the mirrors depends on their type (Rayleigh or Love waves below the surface or pressure (P) and shear (S) waves in the bulk of the rock), their direction, their frequency and their polarisation; properties that must be extracted from the signals of the seismic cage.
Zentrale Fragestellung
Die Arbeit untersucht systematisch, wie eine Verarbeitungspipeline zu gestalten ist, die neben dem eigentlichen Training und Validieren von Machine Learning Modellen, mit einem Fokus auf der Verarbeitung im Frequenzraum, die Validierung gegen die Simulationsmodelle als Closed-Loop realisieren kann. Dabei sind folgende Aspekte zu berücksichtigen:
Variation der Suimulationsmodelle. Mehr oder weniger Seismometer. In-Line (real-time) vs. off-line Kompensation.
Vorverarbeitung und Training auf verteilten Systemem. Neben klassischen Cluster-Computing sollten hier auch Ansätze des Scavanging-Computing berücksichtig werden.
Closed-Loop-Validierung. Direkte Validierung der Machine Learning Modelle in der Simulationsumgebung, d.h. Einbettung der Modelle, z.B. via CICD-Pipelines.
Forschungsdatenmanagement Verwaltung, Persistierung und Publikation der Daten für die weitere Nutzung.
Aufgaben
Die Arbeit muss den aktuellen Stand zu den o.g. Themen mittels Literaturrecherche erheben. Darauf aufbauend ist ein Konzept für eine Pipeline zu entwickeln und Prototypisch unter Nutzung der Resourcen des Big Data Lab zu realisieren und anhang der existierenden Simulationsumgebung an der RWTH zu validieren. Die Simulationsumgebung ist ggf. im Big Data Lab als Zwilling aufzubauen.
Voraussetzungen
Gute Python- und PyTorch-Kenntnisse. Grundlagen in Bild- und/oder Signalverarbeitung, Neuronalen Netzen und Deep Learning. Eigenständige Arbeitsweise und Interesse an Grundlagenforschung/Physik.
Ausgangssituation:
CanControls ist ein innovatives Software-Unternehmen mit Schwerpunkten im Bereich der Echtzeit-Bildverarbeitung, Computer Vision und videobasierten Szenenanalyse.
Von uns entwickelte Technologien kommen in der der Automobilindustrie, der Luft- und Raumfahrt, der Medizintechnik, dem Straßenwesen und der Unterhaltungselektronik zum Einsatz.
Digitale Zwillinge unserer Systeme erlauben es, die Bildgebung/Bildverarbeitung in existierenden Anwendungen zu optimieren, sowie neue Anwendungsfelder digital zu bewerten.
Dafür ist eine möglichst realitiätsnahe Bildsynthese essentiell.
Moderne Methoden der generativen künstlichen Intelligenz stellen hierfür einen vielversprechenden Ansatz dar.
Deine Aufgaben und Vorkenntnisse:
Moderne Verfahren der Bildsynthese berücksichtigen ausschließlich den sichtbaren Wellenlängenbereich in Form von RGB-Bildern.
Ziel dieser Arbeit ist es auf Stable Diffusion basierende Bildsynthese für RGB auf den nicht sichtbaren Wellenlängenbereich zu übertragen.
1. Einarbeitung in Stable Diffusion
2. Recherche gängiger Methoden der „Personalisierung“ etablierter text-to-image Modelle (Textual Inversion, DreamBooth, LoRa, HyperNetworks, etc.)
3. Bewertung dieser Methoden im Kontext unserer proprietären Bilddaten
Vorkenntnisse in Python sowie in gängigen Deep-Learning Bibliotheken (TensorFlow/PyTorch) sind wünschenswert.
Fließendes Englisch in Wort und Schrift ist erforderlich.
Deine Benefits:
1. Du wirst Teil eines internationalen Teams mit Sitz im Zentrum von Aachen
2. Lernen von State-of-the-Art Technologien, in einem Umfeld ohne technische Limitierungen. (Arbeit auf Cluster mit den leistungsfähigsten Grafikkarten zur Zeit der
Ausschreibung)
3. Persönliche Betreuung während des Praktikums.
4. Möglichkeit Teil einer Veröffentlichung auf einer Top-Konferenz zu werden (CVPR, ICCV, ECCV, NeurIPS ).
Ansprechpartner:
[email protected]
Dr. Tarek Luttermann


Informationen zum Unternehmen:
Die SBS Ecoclean Gruppe entwickelt, produziert und vertreibt zukunftsorientierte Anlagen, Systeme und Services für die industrielle Teilereinigung und Entfettung, Ultraschall Feinstreinigung, Hochdruck Wasserstrahlentgraten sowie für die Oberflächenvorbereitung und -behandlung.
Unsere Kunden kommen aus unterschiedlichsten Branchen der Bauteil- und Präzisionsfertigung – wie z.B. Luft- und Raumfahrt, Medizintechnik, Automobil- und Zuliefer-, Hightech-, Halbleiter- und Hochvakuumindustrie, Präzisionsoptik, Mikro- und Feinwerk-, sowie Verbindungstechnik und die Uhren- & Schmuck-Industrie.
Ein weiterer Tätigkeitsbereich ist die Entwicklung und Produktion von alkalischen Elektrolysesystemen für die Erzeugung von grünem Wasserstoff. Als globaler Systemintegrator bieten wir Industrie, Mobilität und Kommunen eine alternative Energiequelle und unterstützen sie so auf dem Weg in eine nachhaltige Zukunft.
Übersicht:
Im Zuge des PerformanceLine-Projektes soll die Optimierung eines neuen Korbs mit zugeordnetem Rezept und flexiblen Prozesszeiten vorangetrieben werden. Dabei stehen die Implementierung einer Online-Prozesszeitveränderung und die Gestaltung eines Portals mit Be-/Entlade-Sequenzen im Fokus.
![]()
Recommender System für Produktionssteuerung:
Bachelor- / Masterarbeit:
- Vorschlag für den Bediener für das nächste zeiteffektivste Rezept / Werkstück => Max. Durchsatz
Masterarbeit:
- Generieren der Fahrbefehle für das Portal unter Einhaltung der festen Prozesszeiten bzw. im zeitlichen Rahmen der flexiblen Prozesszeiten unter in der Maschine befindlichen Körbe / Rezepte
- Maximieren des Durchsatzes unter Berücksichtigung der realen Beladung mit Losgröße „1“.
Ansprechpartner:
Ecoclean GmbH
Rüdiger Fritzen
E-Mail: [email protected]
Telefon: +49 2472 83-243
www.ecoclean-group.net
Informationen zum Unternehmen:
Die SBS Ecoclean Gruppe entwickelt, produziert und vertreibt zukunftsorientierte Anlagen, Systeme und Services für die industrielle Teilereinigung und Entfettung, Ultraschall Feinstreinigung, Hochdruck Wasserstrahlentgraten sowie für die Oberflächenvorbereitung und -behandlung.
Unsere Kunden kommen aus unterschiedlichsten Branchen der Bauteil- und Präzisionsfertigung – wie z.B. Luft- und Raumfahrt, Medizintechnik, Automobil- und Zuliefer-, Hightech-, Halbleiter- und Hochvakuumindustrie, Präzisionsoptik, Mikro- und Feinwerk-, sowie Verbindungstechnik und die Uhren- & Schmuck-Industrie.
Ein weiterer Tätigkeitsbereich ist die Entwicklung und Produktion von alkalischen Elektrolysesystemen für die Erzeugung von grünem Wasserstoff. Als globaler Systemintegrator bieten wir Industrie, Mobilität und Kommunen eine alternative Energiequelle und unterstützen sie so auf dem Weg in eine nachhaltige Zukunft.
Übersicht:
Im Zuge des PerformanceLine-Projektes soll die Optimierung eines neuen Korbs mit zugeordnetem Rezept und flexiblen Prozesszeiten vorangetrieben werden. Dabei stehen die Implementierung einer Online-Prozesszeitveränderung und die Gestaltung eines Portals mit Be-/Entlade-Sequenzen im Fokus.
![]()
KI-Planungssystem für optimale Prozessdurchführung:
Bachelor- / Masterarbeit Maschinenkonfigurationstool:
- Anhand der definierten Taktzeitvorgaben / Durchsatzmenge, Rezepten, Stückzahlen und der Beladereihenfolge
- Bestimmung der Anzahl der Portale zur Erreichung der Vorgaben
- Bestimmung der Anzahl der notwendigen Mehrfach-Prozessstationen zur Erreichung der Vorgaben
Ansprechpartner:
Ecoclean GmbH
Rüdiger Fritzen
E-Mail: [email protected]
Telefon: +49 2472 83-243
www.ecoclean-group.net